CNN as N Gram Detector
CNN has been used intensively in image processing tasks. However, what about in text? is it feasible to use it in text? and what kind of output will it be translated when we’re using CNN in text?
Quoted from Yoav Goldberg’s book
The 1D convolution approach described so far can be thought of as ngram detector. A convolution layer with a windows of size k is learning to identify indicative k-grams in the input.
So when we use 1D CNN on text, we approximate a function to determine which texts or which n-grams are important to a task.
In this short notebook, I will make experiement what kind of “importance” will 1D CNN detect when given a text classification task.
The Setup
First, we begin with the imports…
import torch
import torch.nn as nn
import pandas as pd
from sklearn.model_selection import train_test_split
from tqdm.notebook import tqdm
from torch.utils.data import Dataset, DataLoader
from sklearn.preprocessing import LabelEncoder
from torch.nn import functional as F
from torch.optim import Adam
import numpy as np
from IPython.core.display import HTML
from copy import copy
import matplotlib.pyplot as plt
Dataset Used: BBC News Data
Here, I’ll experiment with BBC News data from kaggle. The data has been pre-downloaded into my disk.
df = pd.read_csv("data/BBC News Train.csv")
Preprocess
First thing first, I’ll make 2 variables texts and labels so I could use scikit’s train_test_split function to split that training data, into 20% test set and the rest will be used to train the model.
texts = df.Text.values
labels = df.Category.values
X_train, X_test, y_train, y_test = train_test_split(
texts, labels, train_size=0.8, random_state=22
)
Next I will define Vocabulary and LabelVocabulary to transform texts and labels into “encoded” version.
class LabelVocabulary(object):
def __init__(self):
self._label_encoder = LabelEncoder()
def fit(self, labels):
self._label_encoder.fit(labels)
def to_index(self, label):
return self._label_encoder.transform([label])[0]
def to_indexes(self, labels):
return self._label_encoder.transform(labels)
def to_labels(self, indexes):
return self._label_encoder.inverse_transform(indexes)
class Vocabulary(object):
def __init__(self, lower=True):
self._itow = {} # index to word
self._wtoi = {} # word to index
self._lower = lower
self.PAD_TOKEN = "<PAD>"
self.PAD_IDX = 10
self.UNK_TOKEN = "<UN[]"
self.UNK_IDX = 0
self.len_vocab = 0
self.max_idx = 0
def _tow(self, word):
if self._lower:
return word.lower()
return word
def wtoi(self, word):
w = self._tow(word)
if w not in self._wtoi:
return self.UNK_IDX
return self._wtoi[w]
def itow(self, i):
if i not in self._itow:
return self.UNK_TOKEN
return self._itow[i]
def fit(self, texts):
i = 100
for text in tqdm(texts):
for word in text.split():
w = self._tow(word)
if w not in self._wtoi:
self._wtoi[w] = i
self._itow[i] = w
i += 1
self.len_vocab = i - 100
self.max_idx = i
return self
def to_padded_idx(self, text, max_seq_len=256):
padded_idxs = []
for word in text.split()[:max_seq_len]:
w = self._tow(word)
word_index = self.wtoi(w)
padded_idxs.append(word_index)
if len(padded_idxs) < max_seq_len:
diff = max_seq_len - len(padded_idxs)
for k in range(diff):
padded_idxs.append(self.PAD_IDX)
return padded_idxs
def to_padded_idxs(self, texts, max_seq_len=256):
res = []
for text in tqdm(texts):
res.append(self.to_padded_idx(text))
return res
def __len__(self):
return self.len_vocab
vocabulary = Vocabulary()
vocabulary.fit(X_train)
label_vocabulary = LabelVocabulary()
label_vocabulary.fit(y_train)
Then I will need to create Dataset abstraction that will be used by pytorch to load data, from
texts = [
'some text here',
...
],
labels = [
'entertainment',
...
]
to
{
'input_ids': [
[20, 52, 78 ...], # assuming 'some' -> 20, 'text' -> 52, 'here' -> 78 by Vocabulary
...
],
'label': [
0, # assuming 0 -> 'entertainment' by LabelVocabulary
...
]
}
class SimpleDataset(Dataset):
def __init__(self, vocab, label_vocab, texts, labels=None, max_seq_len=256):
self._vocab = vocab
self._label_vocab = label_vocab
self._texts = texts
self._labels = labels
self._max_seq_len = max_seq_len
def __len__(self):
return len(self._texts)
def __getitem__(self, idx):
result = {}
result["input_ids"] = torch.tensor(
self._vocab.to_padded_idx(self._texts[idx], max_seq_len=self._max_seq_len),
dtype=torch.long,
)
if self._labels is not None:
result["label"] = torch.tensor(
self._label_vocab.to_index(self._labels[idx]), dtype=torch.long
)
return result
train_dataset = SimpleDataset(vocabulary, label_vocabulary, X_train, y_train)
train_dataloader = DataLoader(train_dataset, batch_size=8)
test_dataset = SimpleDataset(vocabulary, label_vocabulary, X_test, y_test)
test_dataloader = DataLoader(test_dataset, batch_size=8)
Modeling
I will then train a simple model, which has this architecture

The idea is to train a simple classifier and connect the interim output (until Max Pool 1D) back to the ngrams of the sentences.
Here I will define ngrams to be 3, hence the $\text{kernel size} = \text{ngrams} = 3$
class ModelConfig(object):
def __init__(self, vocabulary, label_vocabulary, seq_len=256):
self.vocab_size = vocabulary.max_idx + 1
self.embed_dim = 100
self.cnn_output_dim = 50
self.n_grams = 3 # kernel_size
self.cls_in_dim = (seq_len - (self.n_grams - 1)) // self.n_grams
self.n_class = len(label_vocabulary._label_encoder.classes_)
self.seq_len = seq_len
class SimpleModel(nn.Module):
def __init__(self, config):
super().__init__()
self.embed = nn.Embedding(config.vocab_size, config.embed_dim)
self.cnn = nn.Conv1d(config.embed_dim, config.cnn_output_dim, config.n_grams)
self.max_pool = nn.MaxPool1d(config.n_grams)
self.classifier = nn.Linear(
config.cls_in_dim * config.cnn_output_dim, config.n_class
)
def forward(self, x):
batch_size, seq_len = x.shape
# (batch_size, seq_len, embed_dim)
z = self.embed(x)
# (batch_size, embed_dim, seq_len)
z = z.permute(0, 2, 1)
# (batch_size, cnn_output_dim - kernel_size + 1, seq_len)
z = self.cnn(z)
# max_pool: (batch_size, (cnn_output_dim - kernel_size + 1) / kernel_size, seq_len)
# view: (batch_size, seq_len * (cnn_output_dim - kernel_size + 1) / kernel_size)
z = self.max_pool(z).view(batch_size, -1)
# (batch_size, n_class)
logits = self.classifier(z)
return logits
def accuracy(y_true, y_pred):
batch_size = y_true.shape[0]
return (y_true == y_pred).sum().item() / batch_size
def to_ngram_probs(indices, window_size):
batch_size, out_channel_size, pool_size = indices.shape
batches_w = []
batches = []
for b in range(batch_size):
w = []
x = []
for p in range(pool_size):
indicies_slice = indices[b][:, p]
counts = torch.bincount(indicies_slice, minlength=window_size)
probs = counts / counts.sum()
w.append(counts)
x.append(probs)
batches_w.append(torch.stack(w))
batches.append(torch.stack(x))
return torch.stack(batches_w), torch.stack(batches)
SPAN_START = '<span style="background-color: #FFFF00">'
SPAN_END = "</span>"
def visualize_sentence(sentence, highlight_indexes):
result = []
temp_indexes = copy(highlight_indexes)
for i in range(len(sentence)):
start = -1
end = -1
if len(temp_indexes) > 0:
start, end = temp_indexes[0]
if i == start:
result.append(SPAN_START)
result.append(sentence[i])
if i == end:
result.append(SPAN_END)
temp_indexes.pop(0)
display(HTML(" ".join(result)))
def to_highlight_indexes(important_ngram_idx, ngram_window=2):
highlight_indexes_batch = []
last_batch_idx = -1
for batch_idx, ngram_idx in important_ngram_idx:
if batch_idx > last_batch_idx:
highlight_indexes_batch.append([])
last_batch_idx = batch_idx
start_ngram_idx = ngram_idx
end_ngram_idx = start_ngram_idx + ngram_window
highlight_indexes_batch[-1].append((start_ngram_idx, end_ngram_idx))
return highlight_indexes_batch
def to_words(vocab, batched_ids):
sentences = []
for batch in batched_ids:
sentences.append([vocab.itow(token_id) for token_id in batch])
return sentences
# here I'll use GPU, but CPU will work just fine
device = "cuda"
model_config = ModelConfig(vocabulary, label_vocabulary)
model = SimpleModel(model_config).to(device)
optimizer = Adam(lr=1e-3, params=model.parameters())
now the training loop, I will use epoch=10, no early stopping. My main intention is not fine tuning the model, but to visualize the model output after it has been “fairly” trained.
n_epochs = 10
pbar = tqdm(range(n_epochs))
for epoch in pbar:
epoch_losses = []
epoch_accuracies = []
for batch in train_dataloader:
optimizer.zero_grad()
logits = model(batch["input_ids"].to(device))
_, y_pred = logits.max(dim=1)
labels = batch["label"].to(device)
loss = F.cross_entropy(logits, labels)
batch_loss = loss.item()
epoch_losses.append(batch_loss)
epoch_accuracies.append(accuracy(labels, y_pred))
loss.backward()
optimizer.step()
mean_epoch_losses = np.mean(epoch_losses)
mean_epoch_acc = np.mean(epoch_accuracies)
pbar.set_description(f"[E]loss: {mean_epoch_losses:.3f}, acc: {mean_epoch_acc:.2f}")
Results
To ensure I have a fairly accurate model, I will collect the accuracies from the test dataset.
with torch.no_grad():
test_accuracies = []
test_losses = []
pbar = tqdm(test_dataloader)
for batch in pbar:
logits = model(batch["input_ids"].to(device))
_, y_pred = logits.max(dim=1)
labels = batch["label"].to(device)
loss = F.cross_entropy(logits, labels)
batch_loss = loss.item()
test_losses.append(batch_loss)
test_accuracies.append(accuracy(labels, y_pred))
mean_test_loss = np.mean(test_losses)
mean_test_accuracy = np.mean(test_accuracies)
pbar.set_description(
f"[T]loss: {mean_test_loss:.3f}, acc: {mean_test_accuracy:.2f}"
)
Let’s peek at the test accuracies per batch
plt.boxplot(test_accuracies)
plt.show()
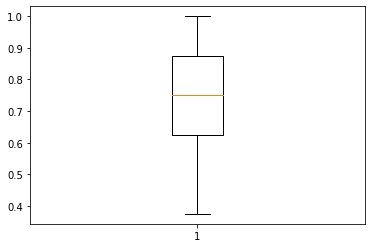
it seems that my simple model has done pretty good job in this text classification dataset, it has median of ~75% accuracy (see the yellow line) for test dataset.
Now I will take a sample from test dataloader and see what will the CNN + pooling detect in our sentences ngrams
test_sample = next(iter(test_dataloader))
with torch.no_grad():
embedded = model.embed(test_sample["input_ids"].to(device))
embedded = embedded.permute(0, 2, 1)
result = model.cnn(embedded)
here I used max_pool1d_with_indices so that I can also extract the indices of max on each sliding window. It pretty much doing the argmax of each sliding window.
# max_pooled (batch_size, seq_len, n_slide/kernel_size)
# indices (batch_size, seq_len, n_slide/kernel_size)
max_pooled, indices = F.max_pool1d_with_indices(result, 3)
then I will construct n_gram_counts with shape [batch_size, pooled_size, n_sliding_windows] that looks like this
[
# batch 1
[
[10, 5, 7, 0, 0, 0],
[ 0, 9, 8, 4, 0, 0],
[ 0, 0, 3, 4, 10, 0],
...
],
...
]
for
$\text{sequence length} = 256$
$\text{kernel size} = 3$
then (also assuming other parameters for CNN is left to default)
\[\text{n sliding windows} = \text{sequence length} - \text{kernel size} + 1 = 254\] \[\text{pooled size} = floor(\frac{\text{n sliding windows}}{\text{kernel size}}) = 84\]# n_gram_counts (batch_size, pooled_size, cnn_output_size)
n_gram_counts, _ = to_ngram_probs(indices, 254)
Then for each sliding windows (was 254 in the previous explanation), we wanted to see which sliding windows are the most important. One way to do that is by summing the count in axis=1 and divide it with maximum of the counts, see this example for illustration
[
# batch 1
[
[10, 5, 7, 0, 0, 0],
[ 0, 9, 8, 4, 0, 0],
[ 0, 0, 3, 4, 10, 0],
...
|
|
v
[10, 14, 18, 8, 0, 0],
|
|
v
[0.55, 0.78, 1.0, 0.44, 0, 0], # divide all by max of those counts, which is 18
],
...
]
sum_per_sliding_windows = n_gram_counts.sum(axis=1)
max_per_batch, _ = sum_per_sliding_windows.max(axis=1)
prob_per_sliding_windows = sum_per_sliding_windows / max_per_batch.view(-1, 1)
Now I’m gonna set arbitrary threshold, 0.8, which seems make sense to me, so that we can filter which sliding windows are seems to be very important from the model point of view and neglect the sliding windows which less than that threshold.
[
[0.55, 0.78, 1.0, 0.44, 0, 0]
|
|
v
[0, 0, 1.0, 0, 0, 0] # zero out all that less than 0.8
]
threshold = 0.8
important_sliding_windows = torch.where(
(prob_per_sliding_windows > threshold) & (prob_per_sliding_windows <= 1.0),
prob_per_sliding_windows,
torch.zeros_like(prob_per_sliding_windows),
)
important_ngram_idx = (
(important_sliding_windows >= threshold).nonzero(as_tuple=True)[0].cpu().numpy()
)
important_ngram_idx = (important_sliding_windows >= threshold).nonzero().cpu().numpy()
highlight_indexes = to_highlight_indexes(important_ngram_idx)
sentences = to_words(vocabulary, test_sample["input_ids"].cpu().numpy())
test_labels = label_vocabulary.to_labels(test_sample["label"].cpu().numpy())
Now I can visualize which ngrams that my model deemed important. The visualize_sentence will highlight important spans in yellow based on the output score of the CNN.
batch_idx = 0
print(f"label : {test_labels[batch_idx]}")
visualize_sentence(sentences[batch_idx], highlight_indexes[batch_idx])
label : entertainment
comeback show for friends star friends actress lisa [UNK] is to play the lead role in a new series about a one-time sitcom star according to the hollywood reporter. [UNK] episodes of comeback have been commissioned by cable channel hbo home of hits such as sex and the city. [UNK] who played [UNK] in friends co-wrote the pilot episode and will also act as executive producer. hbo has been looking for its next big comedy hit since sex and the city drew to a close in the us in february. comeback is the first [UNK] comedy series that the channel has picked up since the sex and the city drew to the end of its [UNK] friends ended its 10-year run on the nbc network in may and attentions have turned to which projects its six individual stars would [UNK] matt [UNK] is starring in a friends spin-off sitcom charting joey s fortunes in los angeles as he [UNK] his acting career. jennifer [UNK] who was rachel in the long-running show has enjoyed a series of successful film appearances with further projects in the [UNK] [UNK] cox [UNK] [UNK] has been working on a drama project along with husband david [UNK] for hbo called the rise and fall of taylor kennedy. matthew perry who played [UNK] has appeared on the west end stage and has a film the beginning of wisdom currently in production. and david [UNK] [UNK] directed during his time on friends and has also worked on [UNK] [UNK] [UNK] [UNK] [UNK] [UNK] [UNK]
batch_idx = 1
print(f"label : {test_labels[batch_idx]}")
visualize_sentence(sentences[batch_idx], highlight_indexes[batch_idx])
label : business
quake s economic costs emerging asian governments and international agencies are reeling at the potential economic devastation left by the asian tsunami and [UNK] world bank president james [UNK] has said his agency is only beginning to grasp the magnitude of the disaster and its economic impact. the tragedy has left at least 25 000 people dead with sri lanka thailand india and indonesia worst hit. some early estimates of reconstruction costs are starting to emerge. millions have been left homeless while businesses and infrastructure have been washed away. economists believe several of the 10 countries hit by the giant waves could see a slowdown in growth. in sri lanka some observers have said that as much as 1% of annual growth may be lost. for thailand that figure is much lower at [UNK] governments are expected to take steps such as cutting taxes and increasing spending to facilitate a recovery. with the enormous [UNK] of [UNK] will be a serious relaxation of fiscal policy [UNK] [UNK] chief economist for the region at [UNK] [UNK] told agence france [UNK] the economic impact of it will certainly be large but it should not be enough to derail the momentum of the region in 2005 he said. first and [UNK] this is a human tragedy. india s economy however is less likely to slow because the areas hit are some of the least developed. the regional giant has enjoyed strong growth in 2004. but india now faces other problems with aid workers under pressure to ensure a clean
batch_idx = 2
print(f"label : {test_labels[batch_idx]}")
visualize_sentence(sentences[batch_idx], highlight_indexes[batch_idx])
label : sport
robben and cole earn chelsea win [UNK] [UNK] a win against a battling portsmouth side just as it looked like the premiership leaders would have to settle for a point. arjen robben curled in a late deflected [UNK] shot from the right side of pompey s box to break the home side s brave [UNK] chelsea had been continually frustrated but joe cole added a second with a 20-yard shot in [UNK] nigel quashie had pompey s best chance when his effort was tipped over. the fratton park crowd were in good voice as usual and even though portsmouth more than held their own chelsea still managed to carve out two early chances. striker didier drogba snapped in an angled shot to force home keeper [UNK] hislop into a smart save while an unmarked frank lampard had a strike blocked by arjan de [UNK] but pompey chased [UNK] and [UNK] a chelsea side as the [UNK] side started to gain the upper hand and almost took the lead through [UNK] the midfielder struck a [UNK] long range shot which keeper petr cech tipped over at full [UNK] pompey stretched arsenal to the limit recently and were providing a similarly tough obstacle to overcome for a chelsea team struggling to [UNK] any pressure. velimir zajec s players stood firm as the visitors came out in lively fashion after the break but just as they took a stranglehold of the match the visitors launched a </span> [UNK] drogba spun to get a sight of goal and struck a fierce
Analysis
We have experiemented to visualize the most important span from a CNN output in text classification task. The CNN seems to have put proper weights on N-grams that have connection to the text class. For example:
| class | Terms |
|---|---|
| entertainment | the nbc network, los angeles as, successful film appearances, … |
| business | agencies are reeling, figure is much, of fiscal policy, … |
| sport | arjen robben curled, fratton park crowd, … |
but there are some terms that pretty general, being marked as important to a class as well. I have not know if the N-grams score has context, such that, if we change the next or before N-grams, the score for the current N-gram will fluctuate?